堆与并查集
堆
-
一棵树,满足每个节点的权值都大于等于/小于等于其叶子节点的权值
-
根节点小的叫小根堆,否则叫大根堆
-
一些堆还能高效的进行
merge、可持久化等操作
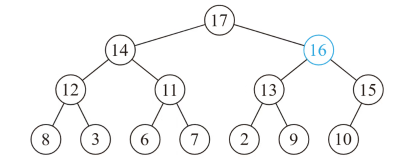
- 向上调整:如果这个节点的权值大于它父亲的权值,就叫换,重复此过程直到不满足或者到根节点
- 复杂度 O(\log n)
- 增加某个点的权值:直接修改后,向上调整一次,但
priority_queue不支持直接修改 - 向下调整:在该节点的儿子中,找一个最大的,与该节点交换,重复此过程直到底层
- 复杂度 O(\log n)
- 插入节点向上调整,删除节点向下调整
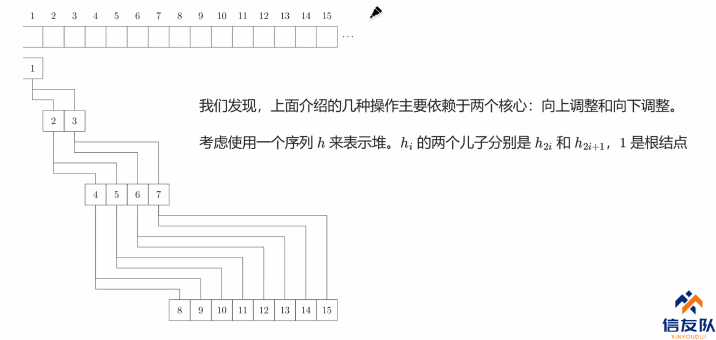
- 建堆:从一个空的堆开始,插入 n 个元素
- 每次都逐个向下调整
- 复杂度 O(\log n-k)
维护一个序列,支持两种操作:
- 向序列中插入一个元素
- 动态维护一个序列上第 k 大的数
-
可以使用对顶堆解决
-
由一个大根堆与一个小根堆组成
-
小根堆维护大值即前 k 大的值(包含第 k 个)
-
大根堆维护小值即比第 k 大数小的其他数

并查集
- 用于管理元素所属集合的数据结构,其本质是一棵树
- 合并(Union):合并两个元素所属集合
- 查询(Find):查询某个元素所属集合
- 优化:路径压缩、按秩合并
- 时间复杂度最坏为 O(m\log n) ,平均为 O(m\alpha(m,n)) ,其中 m\alpha 为反阿克曼函数(在优化的情况下)
- 有 n 个点,初始时均为孤立点
- 接下来有 m 次加边操作,第 i 次操作在 a_i 和 b_i 之间加一条无向边。设 L(i,j) 表示结点 i 和 j 最早在第 L(i,j) 次操作后连通
- 在 m 次操作完后,你要求出 \sum^n_{i=1}\sum^n_{j=i+1}L(i,j) 的值
- 并查集记录子树的大小。考虑统计每次操作的贡献。如果第 i 操作 a_i 和 b_i 分属于两个不同子树,就将这两个子树合并,并将两者子树大小的乘积乘上 i 累加到答案里。
- 有 n 个点,初始时均为孤立点
- 接下来有 m 次加边操作,第 i 次操作在 a_i 和 b_i 之间加一条无向边
- 接下来有 q 次询问,第 i 次询问 u_i 和 v_i 最早在第几次操作后连通
- 考虑在并查集合并的时候记录并查集生成树,也就是说如果第 i 次操作 a_i 和 b_i 分属于两个不同子树,那么吧 (a_i,b_i) 这条边纳入生成树中,边权是 i 。那么查询就是询问 u 到 v 路径上边权的最大值,可以使用树上倍增或树链剖分的方法维护
- 有 n 个点,初始时均为孤立点
- 接下来有 m 次加边操作,第 i 次操作在 a_i 和 b_i 之间加一条无向边
- 接下来有 q 次询问,第 i 次询问第 x_i 个点在第 t_i 次操作后所在连通块大小
当然可以写个可持久化并查集- 离线做法:考虑将询问按 t_i 从小到大排序。在加边的过程中顺便处理询问即可。时间复杂度 O(q\log q+(n+q)\alpha(n))
- 如果强制在线呢?
- 我们只需要求出 x_i 在重构书中最大的一个连通块使得连通中的点权最大值不超过 t_i ,询问的答案按就是这个连通块中点权为 0 的节点个数,即叶子节点个数。
- 由于操作的编号是递增的,因此重构树上父节点的点权总是大于子节点的点权
- 这意味着可以在重构树上从 x_i 到根节点的路径上倍增找到点权最大的不超过 t_i 的结点。
- 时间复杂度 O(n\log n) 。
- 给一个长度为 n 的 \texttt{01} 序列 a_i\dots a_n ,一开始全是 0 ,接下来进行 m 次操作
- 令 a_x=1
- 求 a_n,a_x + 1,\dots a_n 中左数第一个为 0 的位置
- 建立一个并查集, f_i 表示 a_i,a_{i+1},\dots,a_n 中第一个 0 的位置,初始化 f_i=i 。
- 对于一次 a_x=1 的操作,如果 a_x 已经等于 1 则跳过,否则令 f_x=f_{x+1}