
依旧一个非常小笨蛋的做法
n² 预处理 i 是否处于 j 的子树
LCA只有一个点,这个点的所有祖先也是这两个节点的祖先(注意不一定是最近的)
对于每次查询,O(n)遍历一下所有点,找到深度最深的点z的使x和y都处于自己的子树
时间复杂度O(n² + nm)
这样要5e11,CCF的评测机是绝对过不了的
当然这是可以优化的
再预处理一下节点深度
把节点放入对应深度的集合里
这样找节点时只需要找大于等于a和b中深度最大的深度集合进行遍历
也可以直接从根节点dfs,由于LCA的祖先也是ab的祖先,因此每次只会递归一次,当无法递归时,该节点就是a和b的LCA
回归正题
既然是总结帖,那肯定是写正解了
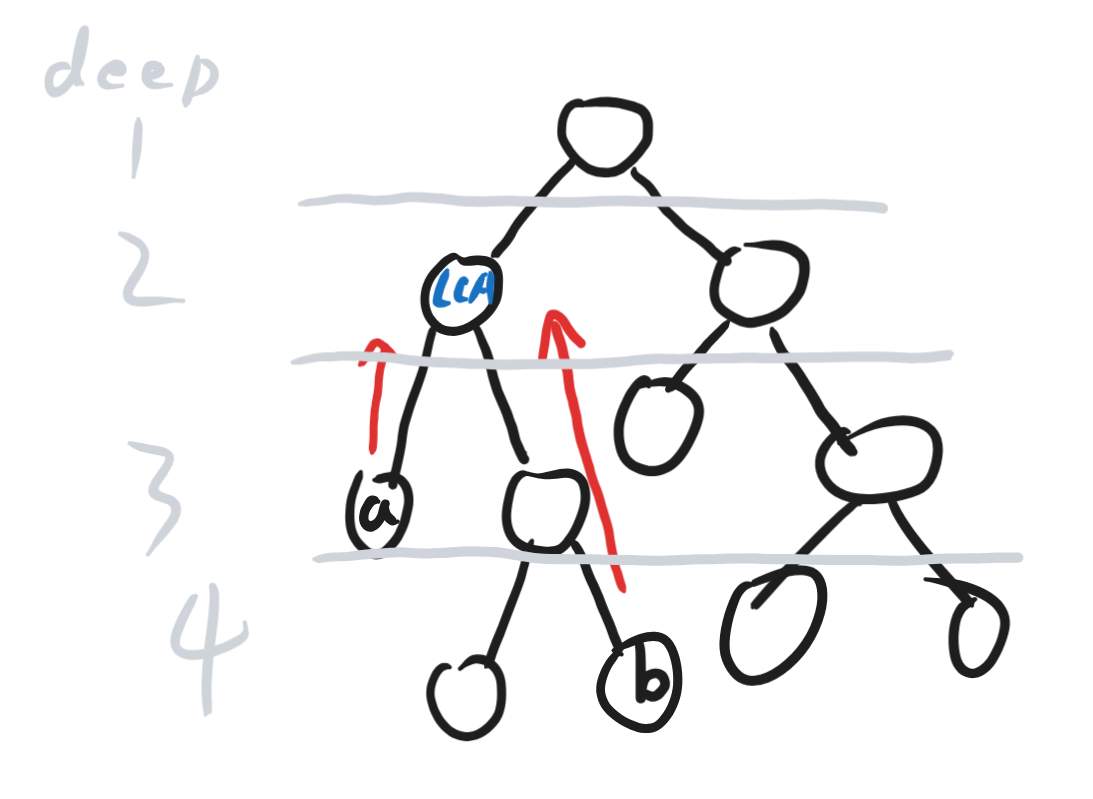
我们可以知道,深度大的节点一定不可能是LCA(祖先的深度不能比儿子大吧?)
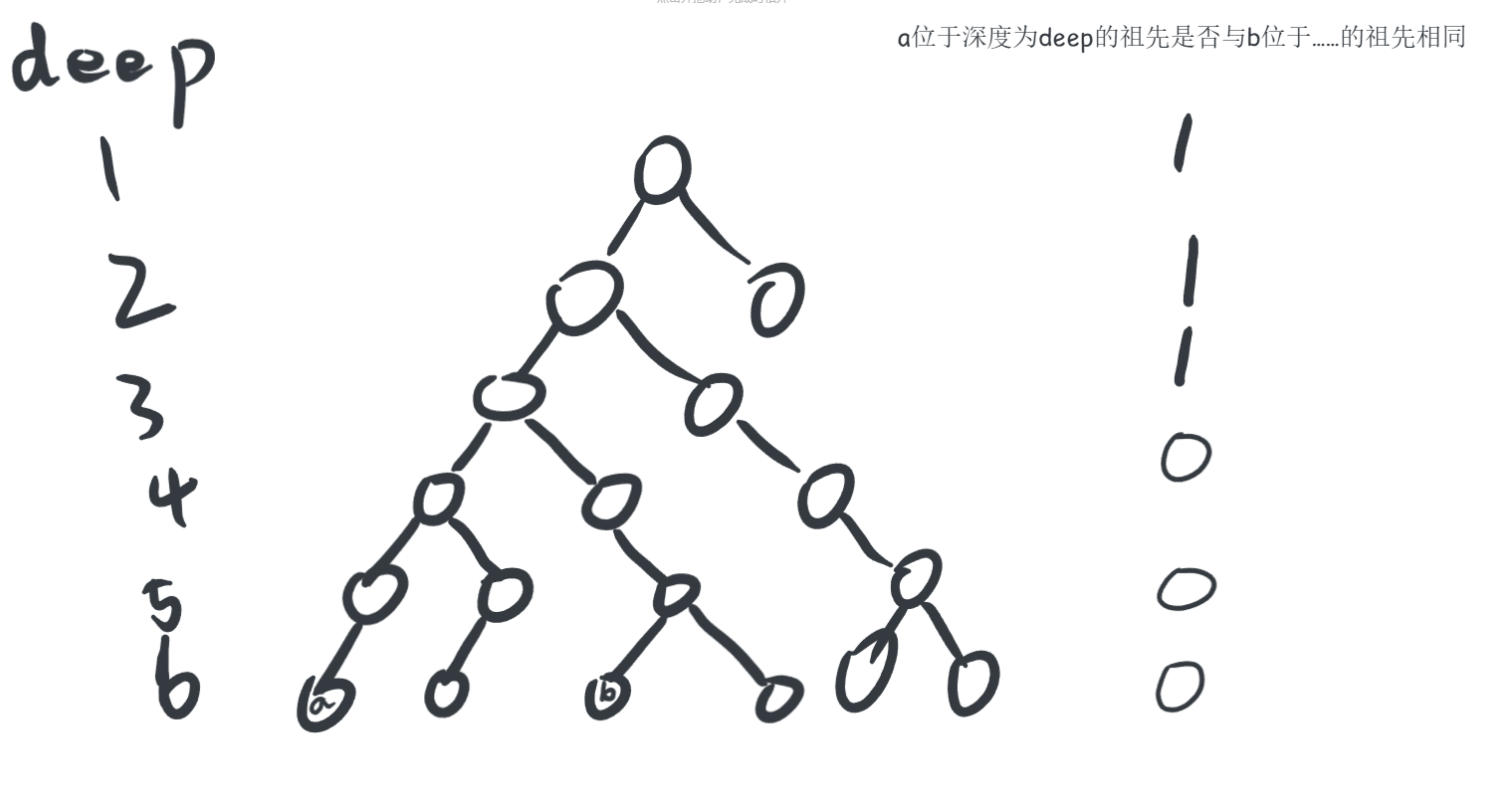
那么我们可以把两个节点深度统一为小的那一个(如下图)
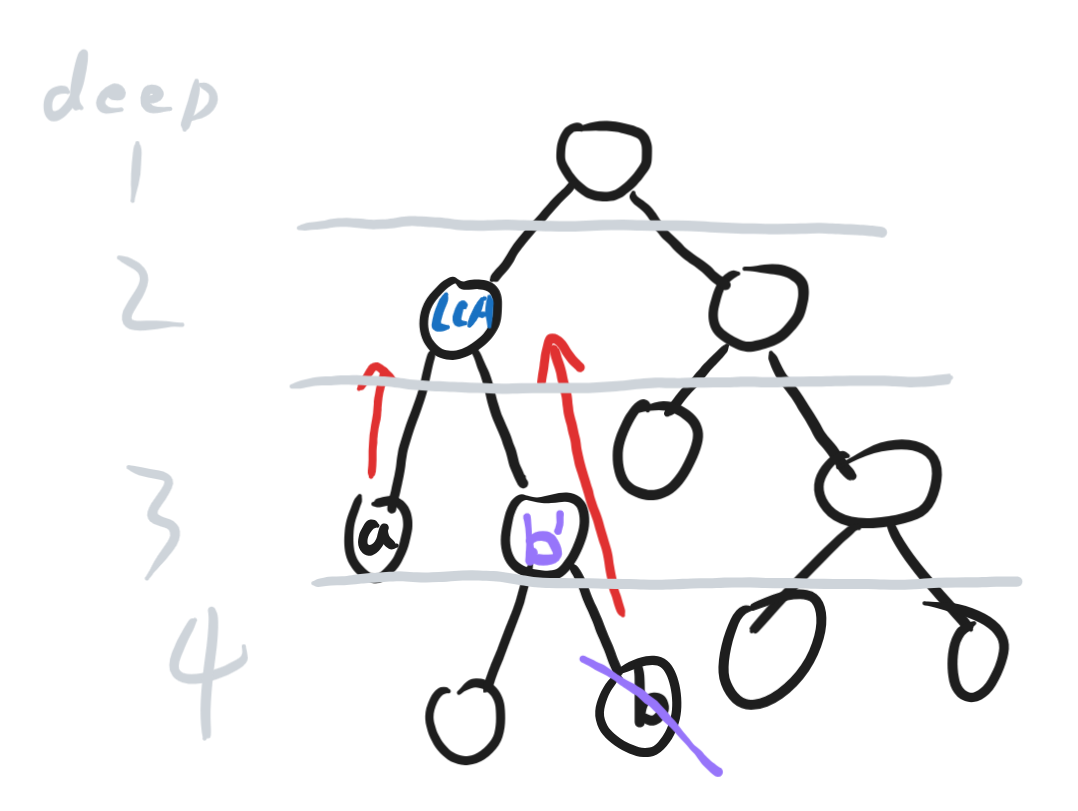
此时只需将两个点同时变为自己的父亲(向上)
直至两个点相同
时间复杂度O(N)
最后时间复杂度O(NM)
(实际上根本没有区别吧)
的确死了,还挺惨
接下来要进行优化
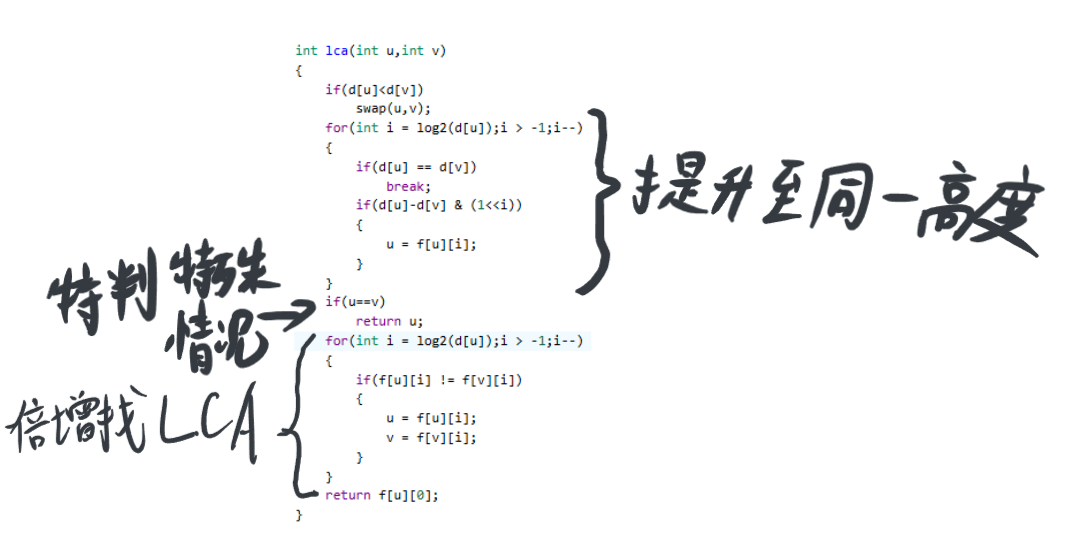
这里建议去看一下倍增
好了,那么接下来讲优化
对于一个形如下图的树
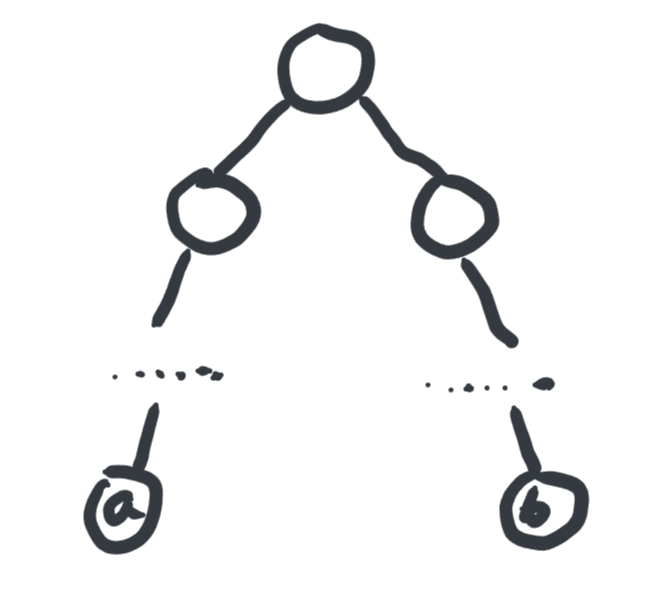
此时求LCA的速度肯定慢
因为它在一步步向上转移的过程中并没有计算出结果
我们肯定希望中间的转移过程尽量简单
这就验证了上文
![]()

 怎么可能没钱
怎么可能没钱