今天进行了标准OI普及组断网测试
得分情况:
| 题目名称 | 做法 | 预计得分 | 实际得分 |
|---|---|---|---|
| A 小信的实践作业 | 语法 | 100 | 0 |
| B 打扫卫生 | 染色/搜索 | 100 | 100 |
| C 小信的文件系统 | 字符串哈希、大模拟 | 0 | 5 |
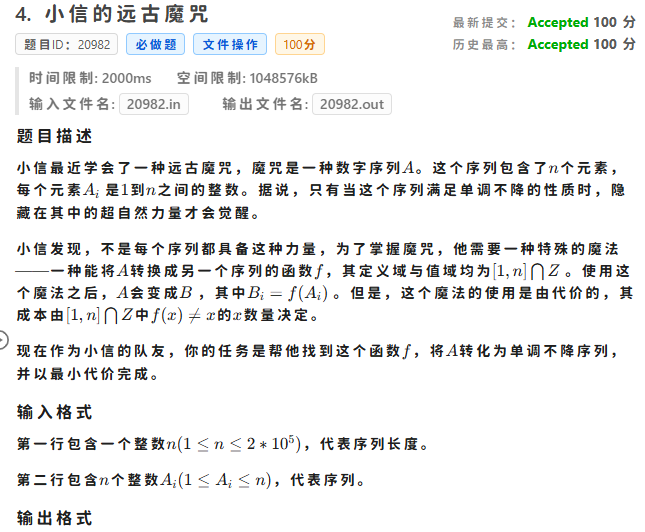
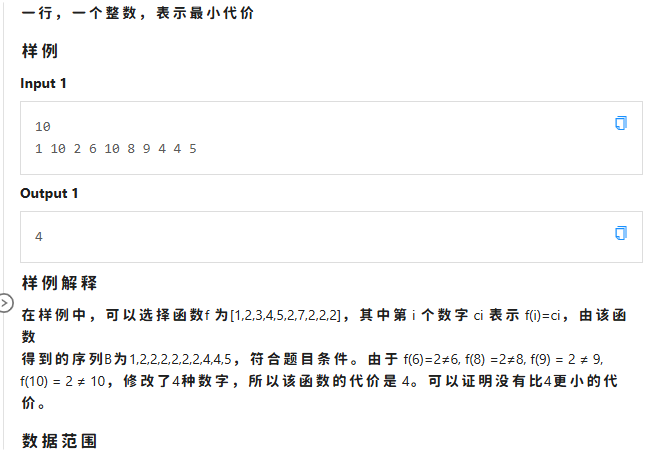
| D 小信的远古魔咒 | 数学 | 0 | 5 |
今天的测试和之前不同,这次我们去了希诺酒店顶层,进行测试(费这么大劲就是为了找一个没有网络的地方,放置有人作弊),而且还是把题目和数据放在压缩包里,解压的密码考试时通知,而且代码也是全部存在文件夹里拷进U盘里的,总之就是为了放置有人作弊
考试过程:
有点紧张,毕竟第一次参加,不知道流程是什么,只能解开压缩包去看题目,发现非常简单,只是打那几个单词略微麻烦,我很快做好了,但是我突然发现,我测样例不对,因为我把单词打错了,把 \LaTeX 覆盖的 v 看成了 u,还好我发现的及时,改了过来,我发现没有地方可以提交,就环视一圈,有点不敢问,只好先把代码放在一边,写后面的题目去了
接着我看到第二题,嗯,看起来十分简单,可是我读了一会题目才发现,原来只能擦规定方格的脏东西,就算其他地方时干净的也不能处理掉,所以就很棘手
后来我突然来了灵感,就是我们前段时间做过的一道题目,好像叫“破墙锤”,用搜索加染色来做,也是连通块问题
这样就能得到除了-1的正确答案,但是-1无法判断,所以我又加了一个数组,来表示理想中的数组(即和地板最接近的可擦完的地板模型),最后看看理想的数组和原数组是否一致,不一致则输出-1
接着我看到第三题,呃,一开始一大串,看的我是头昏眼花,再加上我第二题的优化想来想去辗转改动,脑子根本不够用,所以根本看不懂题目,就停了5分钟
睡醒清醒后我认真读了一遍题目,虽然看起来一大堆,实际上就是一道树的应用拓展+字符串哈希的大模拟,但是我发现那些文件路径的中间没有空格,就非常棘手,我写了半天甚至输入都不对,那后面的肯定不可能对了,我就这样,搞输出搞了1个小时~~,后来我终于放弃了,输出样例骗分
我去到第四题,刚开始发现那个函数公式什么的根本看不懂,后来我慢慢理解了,但是我仍然是一点思绪都没有,再再加上我原来做第二题和第三题耗费了大量的精力,根本做不动,就放弃了,骗了个分
赛后我发现,第一题我![]() 把一个小写
把一个小写o打成了大写O,直接WA0分
不过第二题还算好的,AC了
后两题直接骗分,各得5分
110分,十分不吉利(bushi
主要就是第一题的粗心大意导致流失100分,不然我210分一下子就挤进了前十,成为第六名
题目讲解

非常简单的一道题目,简直是语法中的语法,这基础班都能轻松AC吧!(不像我WA0分,太菜了)
直接统计有大于0的,就res++
最后一堆if和else就可以了
根本都不想亮代码了
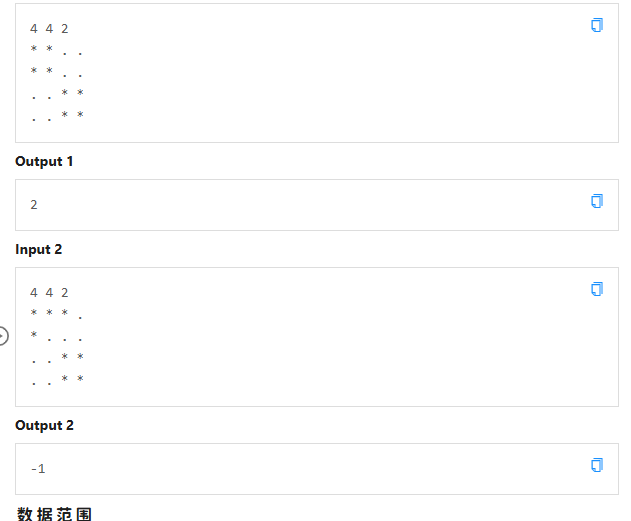
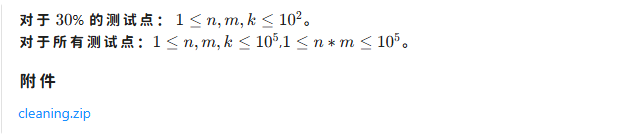
嗯,这题就很有思维含量了,因为他不是哪里都可以擦,可以擦的地方必须都是脏的,那我们每次枚举一个点,如果是脏的就看看以他为抹布左上角的正方形是不是都是脏的(并且不越界),如果越界或不是全脏的那么直接-1
直接这么做还不行呢,因为比如有一个点已经被枚举其他点的时候已经被算作一个抹布的清洁范围了,那么再用它枚举就没有任何意义,甚至会WA重叠,所以我们直接把算过的地板标记成干净的即可(其实不用这么无意义,就是把这部分的脏东西擦掉了),注意这里res++
code
for (int i = 1 ; i <= n ; i++) {
for (int j = 1 ; j <= m ; j++) {
if (mp[i][j] == '*') {
if (i + k - 1 > n || j + k - 1 > m) {
cout << "-1";
return 0;
}
for (int ii = i ; ii <= i + k - 1 ; ii++) {
for (int jj = j ; jj <= j + k - 1 ; jj++) {
if (mp[ii][jj] != '*') {
cout << "-1";
return 0;
}
mp[ii][jj] = '.';
}
}
res++;
}
}
}
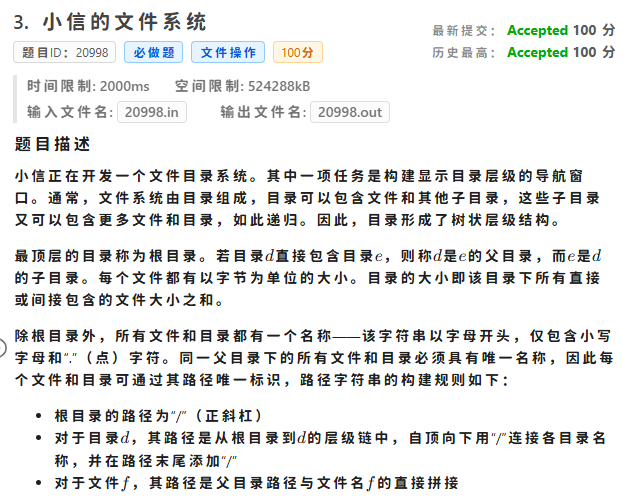

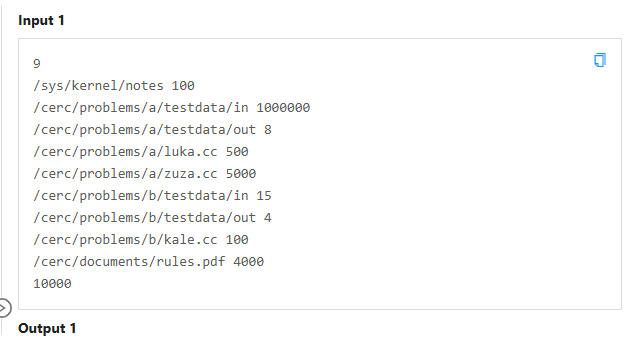
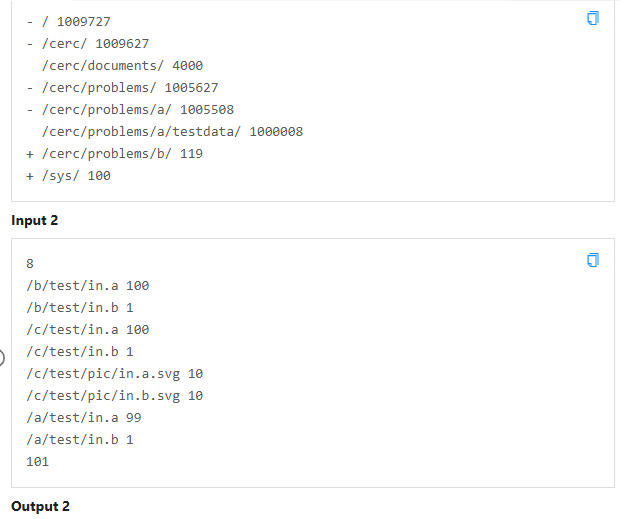



看起来很难一大堆,实际上根本没什么思维含量,就是把所有文件名称映射成一个编号,那这个编号来做树上搜索,最后输出格式与输入格式稍微变一下即可
code
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
const int N = 11010;
map <string, int> id1;
map <int, string> id2;
vector <int> g[N];
set <string> st[N];
int sz[N];
string a;
int t;
bool vist[N];
inline void solve(int x) {
if (vist[x]) return;
int n = g[x].size();
int ans = 0;
int flag = 0;
for (auto y : g[x]) {
if (!vist[y]) {
ans = max(ans, sz[y]);
flag = 1;
}
}
if (flag == 0) {
cout << " " << id2[x] << " " << sz[x] << "\n";
return;
}
if (ans >= t) {
cout << "- " << id2[x] << " " << sz[x] << "\n";
int z = st[x].size();
for (auto it : st[x]) {
string p = it;
solve(id1[p]);
}
return;
} else {
cout << "+ " << id2[x] << " " << sz[x] << "\n";
return;
}
}
inline void dfs(int x) {
int n = g[x].size();
for (auto y : g[x]) {
dfs(y);
sz[x] += sz[y];
}
}
int main() {
freopen("20998.in", "r", stdin);
freopen("20998.out", "w", stdout);
int n, tot = 0;
cin >> n;
for (int i = 1; i <= n; i++) {
int sum;
cin >> a >> sum;
string pre = a;
int l = a.size();
id1[a] = ++tot, id2[tot] = a, vist[tot] = 1, sz[tot] = sum;
for (int i = l - 1; i >= 0; i--) {
if (a[i] == '/') {
string b = a.substr(0, i + 1);
if (!id1.count(b)) {
id1[b] = ++tot, id2[tot] = b;
g[tot].push_back(tot - 1);
st[tot].insert(pre);
pre = b;
} else {
g[id1[b]].push_back(tot);
st[id1[b]].insert(pre);
break;
}
}
}
}
cin >> t;
dfs(id1["/"]);
solve(id1["/"]);
return 0;
}

我们先想到一个很简单的地方,就是如果数字没有相同的话,那么其实就是一个很简单的最长上升子序列。
那么有相同的呢?
其实也很简单,看一组样例:5 2 7 8 5。
两边的数字都是相同的,你会发现,这一坨数字都需要变成一个数字才可以(不是一定要变成两端的),不然肯定不可以。
考虑联通块,那么这些数字就变成了联通块(注意,联通块代表的是数字的值,不是下标)。然后联通块里要选择出来其中的一个数字(也有可能是全部都变成一个新的)作为他们的代表。
接下来用括号来分割开来联通块:
(1 5 4 1)(8)(3 7 6 5 4 3)(10)
这些联通块里我们其实只需要各个选出各自的代表,来组成最后的上升子序列就好了。
此处我们不需要单独处理全部都变成一个新的的那种情况,这里给出的办法是:
把每一个联通块的数字从大到小排列出来(这一步是为了防止最长上升序列一个联通块里找到2个及以上),变成(5 4 1)(8)(7 6 5 4 3)(10)
然后对这个数组求最长上升子序列len,然后用这个数组的总长度减去len就是答案了。
code
#include <bits/stdc++.h>
using namespace std;
const int maxn = 2e5 + 5;
int a[maxn], last[maxn], nxt[maxn];
int n;
int main() {
freopen("20982.in", "r", stdin);
freopen("20982.out", "w", stdout);
ios::sync_with_stdio(false);
cin.tie(0), cout.tie(0);
cin >> n;
for (int i = 1; i <= n; i++) {
cin >> a[i];
last[a[i]] = i; // 记录每个数最后出现的位置
}
for (int i = 1; i <= n; i++) {
nxt[i] = last[a[i]];
}
vector<int> seq; // 最后拼接出的整个数组
for (int l = 1, r; l <= n; ) {
r = l;
set<int> cur;
while (l <= r) {
r = max(r, nxt[l]);
cur.insert(a[l++]);
}
// 将当前联通块内的数字按值从大到小排列加入 seq
vector<int> temp(cur.begin(), cur.end());
//降序配列
sort(temp.begin(), temp.end(),greater<int>());
//加入到seq数组
seq.insert(seq.end(), temp.begin(), temp.end());
}
// 对 seq 求 LIS
int len = 0;
vector<int> lis;
for (int x : seq) {
auto it = lower_bound(lis.begin(), lis.end(), x)-lis.begin();
if (it == lis.size()) lis.push_back(x);
else lis[it] = x;
}
cout << seq.size() - lis.size() << '\n';
return 0;
}