并查集
举例
生活中会产生很多垃圾,这些垃圾处理不好会破坏自然生态
我们可以对垃圾进行分类
- 药物垃圾 – 过期西药
- 易腐垃圾 – 容易腐烂的垃圾
- 厨余垃圾 – 用餐产生的垃圾
- 可回收垃圾 – 可以回收利用的垃圾
- 工业化垃圾 – 工业化的垃圾
- 其他垃圾 – 不属于千5中的垃圾
我们可以发现,这个分类可能会类别太多了,我们可以减少一些种类
直接减少肯定不行,总不能放着那些垃圾不管吧
所以我们需要把几种类型的垃圾 合并,
比如把药物垃圾与工业化垃圾合成有害垃圾,因为他们都对大自然特别有污染性
还可以合并易腐垃圾和厨余垃圾,因为用餐产生的垃圾都易腐烂
这样通过合并,我们就得到了我们平时最常见的四类垃圾
这个合并几个种类的过程称之为
{\Huge 并}
我们现在要丢弃一个纸板箱,我们需要去寻找,哪个垃圾桶可以放置纸板箱
我们通过寻找发现,纸板箱属于可回收垃圾
这个过程我们称之为 {\Huge 查}
而这四个垃圾桶又类似集合一样存储物质,我们给他命名为 \Huge 并查集
并查集的实现
我们用树来当做存数容器
我们的并查集可能有很多不同的分开的树,这代表了不同的类别、家族
这几颗树的根节点就是类别
我们如果要寻找x属于哪个根节点的子孙节点
我们使用递归函数来实现
如果遍历到的点是根节点,就返回根节点的编号
否则继续寻找参数的父节点
(根节点的父节点是自己)
code
int find(int x) {
if (father[x] == x) return x;
return find(father[x]);
}
说完了查找,再解释一下合并,这其实并不难,就是把要合并的两颗树一遍根节点父节点设为另一个根节点的子节点即可
code
void bing(int x, int y) {
int fx = find(x);
int fy = find(y);
if (fx != fy) father[fy] = fx;
}
但是我们想一下,如果这颗子树有很多节点,而且形成一条链,像这样
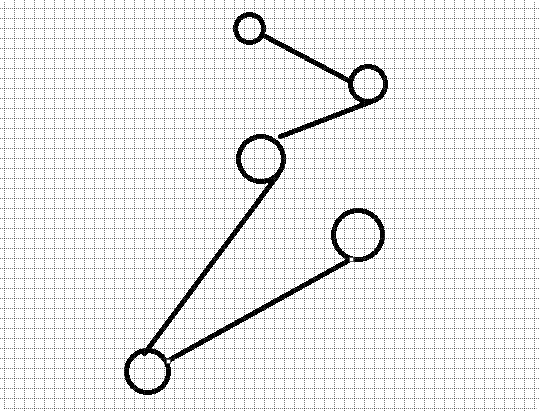
那么遍历得世界复杂度就是 O(n) (n是节点个数)
但是我们发现,并查集就是用来判断关系的,不需要特别的排序,所以我们可以重新排列一下连接每个点的线,像这样
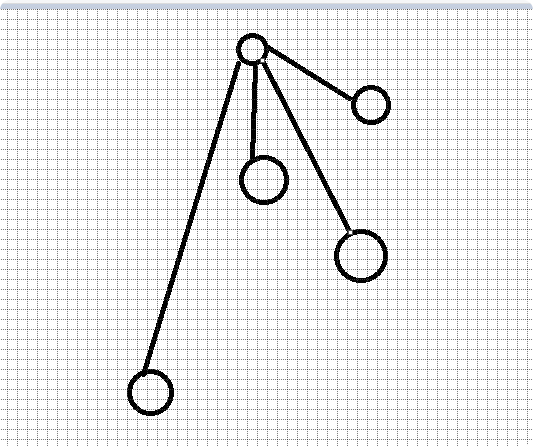
时间复杂度会大大降低到 O(1)
(只需要改查找的代码即可)
code
int find(int x) {
if (father[x] == x) return x;
return father[x] = find(father[x]);
}
这样并查集的只是差不多就讲完了
我们来看几道例题吧!

其实掌握了上面的知识点就差不多了
判断两个人是否是亲戚直接看一下他们的根节点相不相同即可
code
#include <bits/stdc++.h>
using namespace std;
int n, m, p;
int father[5010];
int find(int x) {
if (father[x] == x) return x;
return find(father[x]);
}
void bing(int x, int y) {
int fx = find(x);
int fy = find(y);
if (fx != fy) father[fy] = fx;
}
int main() {
cin >> n >> m >> p;
for (int i = 1 ; i <= n ; i++) {
father[i] = i;
}
for (int i = 1 ; i <= m ; i++) {
int x, y;
cin >> x >> y;
bing(x, y);
}
for (int i = 1 ; i <= p ; i++) {
int x, y;
cin >> x >> y;
if (find(y) == find(x)) {
cout << "Yes\n";
} else {
cout << "No\n";
}
}
return 0;
}
P3958 [NOIP 2017 提高组] 奶酪
题目背景
NOIP2017 提高组 D2T1
题目描述
现有一块大奶酪,它的高度为 h,它的长度和宽度我们可以认为是无限大的,奶酪中间有许多半径相同的球形空洞。我们可以在这块奶酪中建立空间坐标系,在坐标系中,奶酪的下表面为 z = 0,奶酪的上表面为 z = h。
现在,奶酪的下表面有一只小老鼠 Jerry,它知道奶酪中所有空洞的球心所在的坐标。如果两个空洞相切或是相交,则 Jerry 可以从其中一个空洞跑到另一个空洞,特别地,如果一个空洞与下表面相切或是相交,Jerry 则可以从奶酪下表面跑进空洞;如果一个空洞与上表面相切或是相交,Jerry 则可以从空洞跑到奶酪上表面。
位于奶酪下表面的 Jerry 想知道,在不破坏奶酪的情况下,能否利用已有的空洞跑 到奶酪的上表面去?
空间内两点 P_1(x_1,y_1,z_1)、P_2(x_2,y_2,z_2) 的距离公式如下:
$$\mathrm{dist}(P_1,P_2)=\sqrt{(x_1-x_2)^2+(y_1-y_2)^2+(z_1-z_2)^2}$$
输入格式
每个输入文件包含多组数据。
第一行,包含一个正整数 T,代表该输入文件中所含的数据组数。
接下来是 T 组数据,每组数据的格式如下: 第一行包含三个正整数 n,h,r,两个数之间以一个空格分开,分别代表奶酪中空洞的数量,奶酪的高度和空洞的半径。
接下来的 n 行,每行包含三个整数 x,y,z,两个数之间以一个空格分开,表示空洞球心坐标为 (x,y,z)。
输出格式
T 行,分别对应 T 组数据的答案,如果在第 i 组数据中,Jerry 能从下表面跑到上表面,则输出 Yes,如果不能,则输出 No。
输入输出样例 #1
输入 #1
3
2 4 1
0 0 1
0 0 3
2 5 1
0 0 1
0 0 4
2 5 2
0 0 2
2 0 4
输出 #1
Yes
No
Yes
说明/提示
【输入输出样例 1 说明】
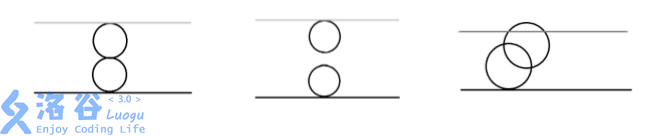
第一组数据,由奶酪的剖面图可见:
第一个空洞在 (0,0,0) 与下表面相切;
第二个空洞在 (0,0,4) 与上表面相切;
两个空洞在 (0,0,2) 相切。
输出 Yes。
第二组数据,由奶酪的剖面图可见:
两个空洞既不相交也不相切。
输出 No。
第三组数据,由奶酪的剖面图可见:
两个空洞相交,且与上下表面相切或相交。
输出 Yes。
【数据规模与约定】
对于 20\% 的数据,n = 1,1 \le h,r \le 10^4,坐标的绝对值不超过 10^4。
对于 40\% 的数据,1 \le n \le 8,1 \le h,r \le 10^4,坐标的绝对值不超过 10^4。
对于 80\% 的数据,1 \le n \le 10^3,1 \le h , r \le 10^4,坐标的绝对值不超过 10^4。
对于 100\% 的数据,1 \le n \le 1\times 10^3,1 \le h , r \le 10^9,T \le 20,坐标的绝对值不超过 10^9。
我们也是用并查集来做
把所有连通的洞洞合在一个树里边
接着双重循环遍历可以钻到奶酪上边或下面的洞洞,看一下有没有一颗树同时拥有着两个洞洞
问题就在于怎么判断两个洞是否相邻
如果两个球的半径之和 ≥ 两个球球心的距离,那么两圆相交(切)。
接下来就是 code
#include <bits/stdc++.h>
#define int long long
//不开long long见祖宗
using namespace std;
int n, h, r;
struct node {
int x, y, z;
int id;
};
node a[100010];
int s1[100010];
int s2[100010];
int father[1010];
int find(int x) {
if (father[x] == x) return father[x];
return father[x] = find(father[x]);
}
void bing(int x, int y) {
int fx = find(x);
int fy = find(y);
if (fx != fy) father[fy] = fx;
}
int check(node c, node d) {
int sum1 = abs(c.x - d.x);
sum1 *= sum1;
int sum2 = abs(c.y - d.y);
sum2 *= sum2;
int sum3 = abs(c.z - d.z);
sum3 *= sum3;
return sum1 + sum2 + sum3;
}
signed main() {
int t;
cin >> t;
while (t--) {
cin >> n >> h >> r;
for (int i = 1 ; i <= n ; i++) father[i] = i;
for (int i = 1 ; i <= n ; i++) {
cin >> a[i].x >> a[i].y >> a[i].z;
a[i].id = i;
}
int cnt1 = 0, cnt2 = 0;
for (int i = 1 ; i <= n ; i++) {
if (a[i].z + r >= h) {
s1[++cnt1] = i;
}
if (a[i].z - r <= 0) {
s2[++cnt2] = i;
}
for (int j = 1 ; j <= i ; j++) {
if ((a[i].x - a[j].x) * (a[i].x - a[j].x) + (a[i].y - a[j].y) * (a[i].y - a[j].y) > 4 * r * r) continue;
if (check(a[i], a[j]) <= 4 * r * r) {
int a1 = find(i);
int a2 = find(j);
if (a1 != a2) {
father[a1] = a2;
}
}
}
}
int s = 0;
for (int i = 1 ; i <= cnt1 ; i++) {
for (int j = 1 ; j <= cnt2 ; j++) {
if (find(s1[i]) == find(s2[j])) {
s = 1;
break;
}
}
if (s == 1) break;
}
if (s == 1) puts("Yes");
else puts("No");
}
return 0;
}
拓扑排序
举例
学科———————前导知识
- 小学数学 ———无
- 小学语文————无
- 小学科学————无
- 初中数学————1
- 初中语文————2
- 初中物理————2、3
- 高中数学————4
- 高中物理————5 、6
- 高中化学————5、6
仔细观察,我们发现除了前3个,每个学科都有前导知识,这些必须先学完前导知识,才能开始学
我们想要合理规划学习顺序,就需要看上面的表格
如果硬看,虽然能看出来,但是如果项目多一点就没办法了,所以我们可以用到一种排序方式,叫做拓扑排序
步骤1:按照表格画一幅有向图,所有知识被其前导知识指向
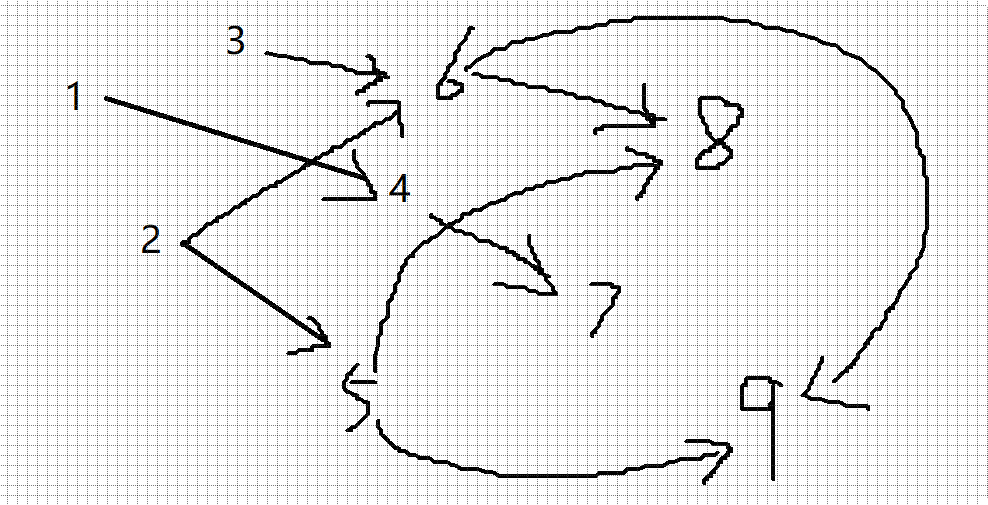
当一个节点入度为0时,我们就先遍历,注意遍历的时候要把所有连着他的线删掉,他指向的节点入度自然也会-1
由于开始可能会有很多选择,中途还有先进先出的规则,那么我们可以用队列来模拟
一开始把入度为0的点入队(for)
接着while循环,遍历每一个对手,出队(跟BFS一样)
随后把他指向的点的入度-1即可,如果减至0,那么把他指向的那个入度为0的点入队
code
for (int i = 1 ; i <= n ; i++) {
int x;
for (; ;) {
cin >> x;
if (x == 0) break;
v[i].push_back(x);
in[x]++;
out[i]++;
}
}
queue <int> q;
for (int i = 1 ; i <= n ; i++) {
if (in[i] == 0) q.push(i);
}
while (!q.empty()) {
int res = q.front();
q.pop();
cout << res << " ";
for (auto i : v[res]) {
in[i]--;
if (in[i] == 0) q.push(i);
}
}
B3644 【模板】拓扑排序 / 家谱树
题目描述
有个人的家族很大,辈分关系很混乱,请你帮整理一下这种关系。给出每个人的后代的信息。输出一个序列,使得每个人的后辈都比那个人后列出。
输入格式
第 1 行一个整数 N ( 1 \le N \le 100 ),表示家族的人数。接下来 N 行,第 i 行描述第 i 个人的后代编号 a_{i,j},表示 a_{i,j} 是 i 的后代。每行最后是 0 表示描述完毕。
输出格式
输出一个序列,使得每个人的后辈都比那个人后列出。如果有多种不同的序列,输出任意一种即可。
输入输出样例 #1
输入 #1
5
0
4 5 1 0
1 0
5 3 0
3 0
输出 #1
2 4 5 3 1
这就是一道模版题,前辈先输出,那么就是前辈指向后辈,随后按上面的思路即可
code
#include <bits/stdc++.h>
using namespace std;
int n;
vector <int> v[110];
int in[110];
int out[110];
int main() {
cin >> n;
for (int i = 1 ; i <= n ; i++) {
int x;
for (; ;) {
cin >> x;
if (x == 0) break;
v[i].push_back(x);
in[x]++;
out[i]++;
}
}
queue <int> q;
for (int i = 1 ; i <= n ; i++) {
if (in[i] == 0) q.push(i);
}
while (!q.empty()) {
int res = q.front();
q.pop();
cout << res << " ";
for (auto i : v[res]) {
in[i]--;
if (in[i] == 0) q.push(i);
}
}
return 0;
}
P1113 杂务
题目描述
John 的农场在给奶牛挤奶前有很多杂务要完成,每一项杂务都需要一定的时间来完成它。比如:他们要将奶牛集合起来,将他们赶进牛棚,为奶牛清洗乳房以及一些其它工作。尽早将所有杂务完成是必要的,因为这样才有更多时间挤出更多的牛奶。
当然,有些杂务必须在另一些杂务完成的情况下才能进行。比如:只有将奶牛赶进牛棚才能开始为它清洗乳房,还有在未给奶牛清洗乳房之前不能挤奶。我们把这些工作称为完成本项工作的准备工作。至少有一项杂务不要求有准备工作,这个可以最早着手完成的工作,标记为杂务 1。
John 有需要完成的 n 个杂务的清单,并且这份清单是有一定顺序的,杂务 k\ (k>1) 的准备工作只可能在杂务 1 至 k-1 中。
写一个程序依次读入每个杂务的工作说明。计算出所有杂务都被完成的最短时间。当然互相没有关系的杂务可以同时工作,并且,你可以假定 John 的农场有足够多的工人来同时完成任意多项任务。
输入格式
第 1 行,一个整数 n\ (3 \le n \le 10{,}000),必须完成的杂务的数目;
第 2 至 n+1 行,每行有一些用空格隔开的整数,分别表示:
- 工作序号(保证在输入文件中是从 1 到 n 有序递增的);
- 完成工作所需要的时间 len\ (1 \le len \le 100);
- 一些必须完成的准备工作,总数不超过 100 个,由一个数字 0 结束。有些杂务没有需要准备的工作只描述一个单独的 0。
保证整个输入文件中不会出现多余的空格。
输出格式
一个整数,表示完成所有杂务所需的最短时间。
输入输出样例 #1
输入 #1
7
1 5 0
2 2 1 0
3 3 2 0
4 6 1 0
5 1 2 4 0
6 8 2 4 0
7 4 3 5 6 0
输出 #1
23
这题可以用拓扑排序完成,但是我有另一种思路:
再每个人物的最晚前导任务完成时开始做(任务可以同时做)
代码非常优雅简洁:
code
#include <bits/stdc++.h>
using namespace std;
int n, t, x, s[10010], res;
int main() {
cin >> n;
for (int i = 1 ; i <= n ; i++) {
cin >> i >> t;
int maxx = 0;
while (cin >> x && x != 0) maxx = max(s[x], maxx);
s[i] = maxx + t;
res = max(s[i], res);
}
cout << res << "\n";
return 0;
}
自行理解
