今天我们来学习c++入门到入土第九节课——不花钱
上一节课,我们讲到了联合体,这节课我们来讲指针
我们先来解答一下问题:
1.问题已在帖子中解决
2.我为短暂的停更表示抱歉
您如有问题的话,可以回复我哦!
我会取前三个问题回答哦
通知
今后会根据上课的内容为大家布置作业,请大家认真完成(不完成我也不知道)
指针
变量的地址、指针
在程序中,我们的数据都有其存储的地址。在程序每次的实际运行过程中,变量在物理内存中的存储位置不尽相同。不过,我们仍能够在编程时,通过一定的语句,来取得数据在内存中的地址。
地址也是数据。存放地址所用的变量类型有一个特殊的名字,叫做「指针变量」,有时也简称做「指针」。
指针变量的大小
指针变量的大小在不同环境下有差异。在 32 位机上,地址用 32 位二进制整数表示,因此一个指针的大小为 4 字节。而 64 位机上,地址用 64 位二进制整数表示,因此一个指针的大小就变成了 8 字节。
所以,指针的大小和你的电脑是几位机有一些关系
地址只是一个刻度一般的数据,为了针对不同类型的数据,「指针变量」也有不同的类型,比如,可以有 int 类型的指针变量,其中存储的地址(即指针变量存储的数值)对应一块大小为 32 位的空间的起始地址;有 char 类型的指针变量,其中存储的地址对应一块 8 位的空间的起始地址。
事实上,用户也可以声明指向指针变量的指针变量。
像我这样:
int *p;
char *q;
double *w;
long long *e;
short *s;
上面的代码就建立了一个int类型的指针变量p,一个char类型的指针变量q,一个double类型的指针变量w,一个long long类型的指针变量e和一个short类型的指针变量s
假如用户自定义了一个结构体:
struct node
{
int a;
int b;
int c;
};
则 node 类型的指针变量,对应32位机的空间是一块 3 × 32 = 96 bit 的空间。
指针的声明与使用
C/C++ 中,指针变量的类型为类型名后加上一个星号 *。比如,int 类型的指针变量的类型名即为 int*。
我们可以使用 & 符号取得一个变量的地址。
要想访问指针变量地址所对应的空间(又称指针所 指向 的空间),需要对指针变量进行 解引用(dereference),使用 * 符号。
int main()
{
int a = 123; // a: 123
int* pa = &a;
*pa = 321; // a: 321
}
对结构体变量也是类似。如果要访问指针指向的结构中的成员,需要先对指针进行解引用,再使用 . 成员关系运算符。不过,更推荐使用「箭头」运算符 -> 这一更简便的写法。
struct node
{
int a;
int b;
int c;
};
int main()
{
node x{1, 2, 3}, y{6, 7, 8};
node* px = &x;
(*px) = y; // x: {6,7,8}
(*px).a = 4; // x: {4,7,8}
px->b = 5; // x: {4,5,8}
}
指针的偏移
指针变量也可以 和整数 进行加减操作。对于 int 型指针,每加 1(递增 1),其指向的地址偏移 32 位(即 4 个字节);若加 2,则指向的地址偏移 2 × 32 = 64 位。同理,对于 char 型指针,每次递增,其指向的地址偏移 8 位(即 1 个字节)。
使用指针偏移访问数组
我们前面说过,数组是一块连续的存储空间。而在 C/C++ 中,直接使用数组名,得到的是数组的起始地址。
int main()
{
int a[3] = {1, 2, 3};
int* p = a; // p 指向 a[0]
*p = 4; // a: [4, 2, 3]
p = p + 1; // p 指向 a[1]
*p = 5; // a: [4, 5, 3]
p++; // p 指向 a[2]
*p = 6; // a: [4, 5, 6]
}
当通过指针访问数组中的元素时,往往需要用到「指针的偏移」,换句话说,即通过一个基地址(数组起始的地址)加上偏移量来访问。
我们常用 [] 运算符来访问数组中某一指定偏移量处的元素。比如 a[3] 或者 p[4]。这种写法和对指针进行运算后再引用是等价的,即 p[4] 和 *(p + 4) 是等价的两种写法。
空指针
在 C++11 之前,C++ 和 C 一样使用 NULL 宏表示空指针常量,C++ 中 NULL 的实现一般如下:
// C++11 前 #define NULL 0
C 语言对 NULL 的定义
C 语言在 C23 前有两个 NULL 的定义,只有类型不同:一个是整型常量表达式,一个是转换为 void * 类型的常量表达式,但其值都为 0,编译器可任选一个实现。
空指针和整数 0 的混用在 C++ 中会导致许多问题,比如:
int f(int x);
int f(int* p);
在调用 f(NULL) 时,实际调用的函数的类型是 int(int) 而不是 int(int *).
NULL 在 C 语言中造成的问题
比起在 C++ 中,因为有两个定义,在 C 语言中 NULL 造成的问题更为严重:如果在一个传递可变参数的函数中,函数编写者想要接受一个指针,但是函数调用者传递了一个定义为整型的 NULL,则会造成未定义行为,因在函数内使用传入的可变参数时,要进行类型转换,而从整型到指针类型的转换是未定义行为。
为了解决这些问题,C++11 引入了 nullptr 关键字作为空指针常量。
C++ 规定 nullptr 可以隐式转换为任何指针类型,这种转换结果是该类型的空指针值。
nullptr 的类型为 std::nullptr_t, 称作空指针类型,可能的实现如下:
namespace std
{
typedef decltype(nullptr) nullptr_t;
}
另外,C++11 起 NULL 宏的实现也被修改为了:
// C++11 起 #define NULL nullptr
C 语言对空指针常量的改进
基于类似的原因,C23 也引入了 nullptr 作为空指针常量,同时引入了 nullptr_t 作为其类型
指针的进阶使用
使用指针,使得程序编写者可以操作程序运行时中各处的数据,而不必局限于作用域。
指针类型参数的使用
在 C/C++ 中,调用函数(过程)时使用的参数,均以拷贝的形式传入子过程中(引用除外,会在后续介绍)。默认情况下,函数仅能通过返回值,将结果返回到调用处。但是,如果某个函数希望修改其外部的数据,或者某个结构体/类的数据量较为庞大、不宜进行拷贝,这时,则可以通过向其传入外部数据的地址,便得以在其中访问甚至修改外部数据。
下面的 my_swap 方法,通过接收两个 int 型的指针,在函数中使用中间变量,完成对两个 int 型变量值的交换。
void my_swap(int *a, int *b)
{
int t;
t = *a;
*a = *b;
*b = t;
}
int main()
{
int a = 6, b = 10;
my_swap(&a, &b); // 调用后,main 函数中 a 变量的值变为 10,b 变量的值变为 6
}
C++ 中引入了引用的概念,相对于指针来说,更易用,也更安全。
动态实例化
除此之外,程序编写时往往会涉及到动态内存分配,即,程序会在运行时,向操作系统动态地申请或归还存放数据所需的内存。当程序通过调用操作系统接口申请内存时,操作系统将返回程序所申请空间的地址。要使用这块空间,我们需要将这块空间的地址存储在指针变量中。
在 C++ 中,我们使用 new 运算符来获取一块内存,使用 delete 运算符释放某指针所指向的空间。
int* p = new int(1234); /* ... */ delete p;
上面的语句使用 new 运算符向操作系统申请了一块 int 大小的空间,将其中的值初始化为 1234,并声明了一个 int 型的指针 p 指向这块空间。
同理,也可以使用 new 开辟新的对象:
class A
{
int a;
public:A(int a_) : a(a_)
{
...
}
};
int main()
{
A* p = new A(1234);
/* ... */
delete p;
}
如上,「new 表达式」将尝试开辟一块对应大小的空间,并尝试在这块空间上构造这一对象,并返回这一空间的地址。
struct node
{
int a;
int b;
int c;
};
int main()
{
node* p = new node{1, 2, 3}; //p.a = 1, p.b = 2, p.c = 3
/* ... */
delete p;
}
列表初始化
{} 运算符可以用来初始化没有构造函数的结构。除此之外,使用 {} 运算符可以使得变量的初始化形式变得统一。
需要注意,当使用 new 申请的内存不再使用时,需要使用 delete 释放这块空间。不能对一块内存释放两次或以上。而对空指针 nullptr 使用 delete 操作是合法的。
动态创建数组
也可以使用 new[] 运算符创建数组,这时 new[] 运算符会返回数组的首地址,也就是数组第一个元素的地址,我们可以用对应类型的指针存储这个地址。释放时,则需要使用 delete[] 运算符。
size_t element_cnt = 5;
int *p = new int[element_cnt];
delete[] p;
数组中元素的存储是连续的,即 p + 1 指向的是 p 的后继元素。
二维数组
在存放矩阵形式的数据时,可能会用到「二维数组」这样的数据类型。从语义上来讲,二维数组是一个数组的数组。而计算机内存可以视作一个很长的一维数组。要在计算机内存中存放一个二维数组,便有「连续」与否的说法。
所谓「连续」,即二维数组的任意一行(row)的末尾与下一行的起始,在物理地址上是毗邻的,换言之,整个二维数组可以视作一个一维数组;反之,则二者在物理上不一定相邻。
对于「连续」的二维数组,可以仅使用一个循环,借由一个不断递增的指针即可遍历数组中的所有数据。而对于非连续的二维数组,由于每一行不连续,则需要先取得某一行首的地址,再访问这一行中的元素。
二维数组的存储方式
这种按照「行(row)」存储数据的方式,称为行优先存储;相对的,也可以按照列(column)存储数据。由于计算机内存访问的特性,一般来说,访问连续的数据会得到更高的效率。因此,需要按照数据可能的使用方式,选择「行优先」或「列优先」的存储方式。
动态创建二维数组
在 C/C++ 中,我们可以使用类似下面这样的语句声明一个 N 行(row)M 列(column)的二维数组,其空间在物理上是连续的。
描述数组的维度
更通用的方式是使用第 n 维(dimension)的说法。对于「行优先」的存储形式,数组的第一维长度为 N,第二维长度为 M。
int a[N][M];
这种声明方式要求 N 和 M 为在编译期即可确定的常量表达式。
在 C/C++ 中,数组的第一个元素下标为 0,因此 a[r][c] 这样的式子代表二维数组 a 中第 r + 1 行的第 c + 1 个元素,我们也称这个元素的下标为 (r,c)。
不过,实际使用中,(二维)数组的大小可能不是固定的,需要动态内存分配。
常见的方式是声明一个长度为 N × M 的 一维数组,并通过下标 r * M + c 访问二维数组中下标为 (r, c) 的元素。
int* a = new int[N * M];
这种方法可以保证二维数组是 连续的。
数组在物理层面上的线性存储
实际上,数据在内存中都可以视作线性存放的,因此在一定的规则下,通过动态开辟一维数组的空间,即可在其上存储 n 维的数组。
此外,亦可以根据「数组的数组」这一概念来进行内存的获取与使用。对于一个存放的若干数组的数组,实际上为一个存放的若干数组的首地址的数组,也就是一个存放若干指针变量的数组。
我们需要一个变量来存放这个「数组的数组」的首地址——也就是一个指针的地址。这个变量便是一个「指向指针的指针」,有时也称作「二重指针」,如:
int** a = new int*[5];
接着,我们需要为每一个数组申请空间:
for (int i = 0; i < 5; i++)
{
a[i] = new int[5];
}
至此,我们便完成了内存的获取。而对于这样获得的内存的释放,则需要进行一个逆向的操作:即先释放每一个数组,再释放存储这些数组首地址的数组,如:
for (int i = 0; i < 5; i++)
{
delete[] a[i];
}
delete[] a;
需要注意,这样获得的二维数组,不能保证其空间是连续的。
还有一种方式,需要使用到「指向数组的指针」。
数组名和数组首元素地址的区别
我们之前说到,在 C/C++ 中,直接使用数组名,值等于数组首元素的地址。但是数组名表示的这一变量的类型实际上是整个数组,而非单个元素。
int main()
{
int a[5] = {1, 2, 3, 4, 5};
}
从概念上说,代码中标识符 a 的类型是 int[5];从实际上来说,a + 1 所指向的地址相较于 a 指向的地址的偏移量为 5 个 int 型变量的长度。
int main()
{
int(*a)[5] = new int[5][5];
int* p = a[2];
a[2][1] = 1;
delete[] a;
}
这种方式获得到的也是连续的内存,但是可以直接使用 a[n] 的形式获得到数组的第 n + 1 行(row)的首地址,因此,使用 a[r][c] 的形式即可访问到下标为 (r, c) 的元素。
由于指向数组的指针也是一种确定的数据类型,因此除数组的第一维外,其他维度的长度均须为一个能在编译器确定的常量。不然,编译器将无法翻译如 a[n] 这样的表达式(a 为指向数组的指针)。
指向函数的指针
简单地说,要调用一个函数,需要知晓该函数的参数类型、个数以及返回值类型,这些也统一称作接口类型。
可以通过函数指针调用函数。有时候,若干个函数的接口类型是相同的,使用函数指针可以根据程序的运行 动态地 选择需要调用的函数。换句话说,可以在不修改一个函数的情况下,仅通过修改向其传入的参数(函数指针),使得该函数的行为发生变化。
假设我们有若干针对 int 类型的二元运算函数,则函数的参数为 2 个 int,返回值亦为 int。下边是一个使用了函数指针的例子:
#include <bits/stdc++.h>
using namespace std;
int (*p)(int, int);
int foo1(int a, int b)
{
return a * b + b;
}
int foo2(int a, int b)
{
return (a + b) * b;
}
int main()
{
int op;
cin >> op;
if (op == 1)
{
p = foo1;
}
else
{
p = foo2;
}
int m, n;
cin >> m >> n;
cout << p(m, n);
return 0;
}
&、* 和函数指针
在 C 语言中,诸如 void (*p)() = foo;、void (*p)() = &foo;、void (*p)() = *foo;、void (*p)() = ***foo 等写法的结果是一样的。
因为函数(如 foo)是能够被隐式转换为指向函数的指针的,因此 void (*p)() = foo; 的写法能够成立。
使用 & 运算符可以取得到对象的地址,这对函数也是成立的,因此 void (*p)() = &foo; 的写法仍然成立。
对函数指针使用 * 运算符可以取得指针指向的函数,而对于 **foo 这样的写法来说,*foo 得到的是 foo 这个函数,紧接着又被隐式转换为指向 foo 的指针。如此类推,**foo 得到的最终还是指向 foo 的函数指针;用户尽可以使用任意多的 *,结果也是一样的。
同理,在调用时使用类似 (*p)() 和 p() 的语句是一样的,可以省去 * 运算符。
可以使用 typedef 关键字声明函数指针的类型。
typedef int (*p_bi_int_op)(int, int);
这样我们就可以在之后使用 p_bi_int_op 这种类型,即指向「参数为 2 个 int,返回值亦为 int」的函数的指针。
可以通过使用 std::function 来更方便的引用函数。(未完待续)
使用函数指针,可以实现「回调函数」。(未完待续)
作业:
1. P1001 A+B Problem
难度:入门
思路: 这是一个非常基础的题目,要求输入两个整数并输出它们的和。虽然题目本身不涉及指针,但可以通过指针来实现。
C++代码:
#include <bits/stdc++.h>
using namespace std;
int main()
{
int a, b;
cin >> a >> b;
int *pa = &a, *pb = &b;
cout << *pa + *pb << endl;
return 0;
}
2. P1428 小鱼比可爱
难度:普及-
思路: 题目要求比较数组中每个元素与它前面的元素的大小关系。可以通过指针遍历数组来实现。
C++代码:
#include <bits/stdc++.h>
using namespace std;
int main()
{
int n;
cin >> n;
int a[n];
for (int i = 0; i < n; ++i)
{
cin >> a[i];
}
for (int i = 0; i < n; ++i)
{
int count = 0;
for (int j = 0; j < i; ++j)
{
if (a[j] < a[i])
{
count++;
}
}
cout << count << " ";
}
return 0;
}
3. P1047 校门外的树
难度:普及/提高-
思路: 题目要求计算一段区间内树的数量。可以通过指针来操作数组,标记被移走的树。
C++代码:
#include <bits/stdc++.h>
using namespace std;
int main()
{
int L, M;
cin >> L >> M;
int *trees = new int[L + 1]();
for (int i = 0; i < M; ++i)
{
int start, end;
cin >> start >> end;
for (int j = start; j <= end; ++j)
{
trees[j] = 1;
}
}
int count = 0;
for (int i = 0; i <= L; ++i)
{
if (trees[i] == 0)
{
count++;
}
}
cout << count << endl;
delete[] trees;
return 0;
}
4. P1090 合并果子
难度:普及/提高-
思路: 题目要求合并果子的最小体力消耗。可以使用优先队列(堆)来实现,但也可以通过指针操作数组来模拟堆的行为。
C++代码:
#include <bits/stdc++.h>
using namespace std;
int main()
{
int n;
cin >> n;
priority_queue<int, vector<int>, greater<int>> pq;
for (int i = 0; i < n; ++i)
{
int fruit;
cin >> fruit;
pq.push(fruit);
}
int total = 0;
while (pq.size() > 1)
{
int a = pq.top();
pq.pop();
int b = pq.top();
pq.pop();
total += a + b;
pq.push(a + b);
}
cout << total << endl;
return 0;
}
5. P1886 滑动窗口
难度:普及+/提高
思路: 题目要求在一个数组中滑动窗口,找出每个窗口的最大值和最小值。可以使用双指针技巧来优化滑动窗口的操作。
C++代码:
#include <bits/stdc++.h>
using namespace std;
const int MAXN = 1e6 + 10;
int a[MAXN];
void my_min(int n, int k)
{
deque<int> dq;
for (int i = 0; i < n; ++i)
{
while (!dq.empty() && a[dq.back()] >= a[i])
{
dq.pop_back();
}
dq.push_back(i);
while (dq.front() <= i - k)
{
dq.pop_front();
}
if (i >= k - 1)
{
cout << a[dq.front()] << " ";
}
}
cout << endl;
}
void my_max(int n, int k)
{
deque<int> dq;
for (int i = 0; i < n; ++i)
{
while (!dq.empty() && a[dq.back()] <= a[i])
{
dq.pop_back();
}
dq.push_back(i);
while (dq.front() <= i - k)
{
dq.pop_front();
}
if (i >= k - 1)
{
cout << a[dq.front()] << " ";
}
}
cout << endl;
}
int main()
{
int n, k;
cin >> n >> k;
for (int i = 0; i < n; ++i)
{
cin >> a[i];
}
my_min(n, k);
my_max(n, k);
return 0;
}
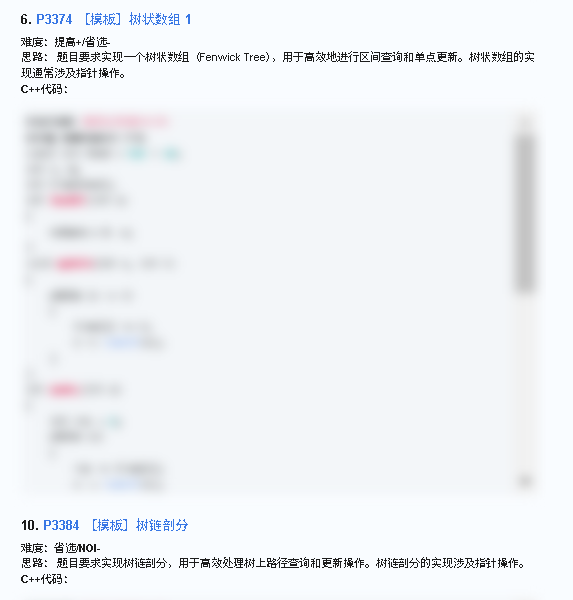
6. P3374 【模板】树状数组 1
难度:提高+/省选-
思路: 题目要求实现一个树状数组(Fenwick Tree),用于高效地进行区间查询和单点更新。树状数组的实现通常涉及指针操作。
C++代码:
#include <bits/stdc++.h>
using namespace std;
const int MAXN = 5e5 + 10;
int n, m;
int tree[MAXN];
int lowbit(int x)
{
return x & -x;
}
void update(int x, int k)
{
while (x <= n)
{
tree[x] += k;
x += lowbit(x);
}
}
int query(int x)
{
int res = 0;
while (x)
{
res += tree[x];
x -= lowbit(x);
}
return res;
}
int main()
{
cin >> n >> m;
for (int i = 1; i <= n; ++i)
{
int a;
cin >> a;
update(i, a);
}
for (int i = 0; i < m; ++i)
{
int op, x, y;
cin >> op >> x >> y;
if (op == 1)
{
update(x, y);
}
else
{
cout << query(y) - query(x - 1) << endl;
}
}
return 0;
}
7. P3384 【模板】树链剖分
难度:省选/NOI-
思路: 题目要求实现树链剖分,用于高效处理树上路径查询和更新操作。树链剖分的实现涉及指针操作。
C++代码:
#include <bits/stdc++.h>
using namespace std;
const int MAXN = 1e5 + 10;
int n, m, r, mod;
int a[MAXN], fa[MAXN], dep[MAXN], siz[MAXN], son[MAXN], top[MAXN], dfn[MAXN], rnk[MAXN], cnt;
vector<int> G[MAXN];
void dfs1(int u, int f)
{
fa[u] = f;
dep[u] = dep[f] + 1;
siz[u] = 1;
for (int v : G[u])
{
if (v == f) continue;
dfs1(v, u);
siz[u] += siz[v];
if (siz[v] > siz[son[u]])
{
son[u] = v;
}
}
}
void dfs2(int u, int t)
{
top[u] = t;
dfn[u] = ++cnt;
rnk[cnt] = u;
if (!son[u]) return;
dfs2(son[u], t);
for (int v : G[u])
{
if (v == fa[u] || v == son[u]) continue;
dfs2(v, v);
}
}
struct SegmentTree
{
long long tree[MAXN << 2], add[MAXN << 2];
void push_up(int p)
{
tree[p] = (tree[p << 1] + tree[p << 1 | 1]) % mod;
}
void push_down(int p, int l, int r)
{
if (add[p])
{
int mid = (l + r) >> 1;
tree[p << 1] = (tree[p << 1] + add[p] * (mid - l + 1)) % mod;
tree[p << 1 | 1] = (tree[p << 1 | 1] + add[p] * (r - mid)) % mod;
add[p << 1] = (add[p << 1] + add[p]) % mod;
add[p << 1 | 1] = (add[p << 1 | 1] + add[p]) % mod;
add[p] = 0;
}
}
void build(int p, int l, int r)
{
if (l == r)
{
tree[p] = a[rnk[l]] % mod;
return;
}
int mid = (l + r) >> 1;
build(p << 1, l, mid);
build(p << 1 | 1, mid + 1, r);
push_up(p);
}
void update(int p, int l, int r, int ql, int qr, long long k)
{
if (ql <= l && r <= qr)
{
tree[p] = (tree[p] + k * (r - l + 1)) % mod;
add[p] = (add[p] + k) % mod;
return;
}
push_down(p, l, r);
int mid = (l + r) >> 1;
if (ql <= mid) update(p << 1, l, mid, ql, qr, k);
if (qr > mid) update(p << 1 | 1, mid + 1, r, ql, qr, k);
push_up(p);
}
long long query(int p, int l, int r, int ql, int qr)
{
if (ql <= l && r <= qr)
{
return tree[p];
}
push_down(p, l, r);
int mid = (l + r) >> 1;
long long res = 0;
if (ql <= mid) res = (res + query(p << 1, l, mid, ql, qr)) % mod;
if (qr > mid) res = (res + query(p << 1 | 1, mid + 1, r, ql, qr)) % mod;
return res;
}
} st;
void update_path(int u, int v, long long k)
{
while (top[u] != top[v])
{
if (dep[top[u]] < dep[top[v]]) swap(u, v);
st.update(1, 1, n, dfn[top[u]], dfn[u], k);
u = fa[top[u]];
}
if (dep[u] > dep[v]) swap(u, v);
st.update(1, 1, n, dfn[u], dfn[v], k);
}
long long query_path(int u, int v)
{
long long res = 0;
while (top[u] != top[v])
{
if (dep[top[u]] < dep[top[v]]) swap(u, v);
res = (res + st.query(1, 1, n, dfn[top[u]], dfn[u])) % mod;
u = fa[top[u]];
}
if (dep[u] > dep[v]) swap(u, v);
res = (res + st.query(1, 1, n, dfn[u], dfn[v])) % mod;
return res;
}
void update_subtree(int u, long long k)
{
st.update(1, 1, n, dfn[u], dfn[u] + siz[u] - 1, k);
}
long long query_subtree(int u)
{
return st.query(1, 1, n, dfn[u], dfn[u] + siz[u] - 1);
}
int main()
{
cin >> n >> m >> r >> mod;
for (int i = 1; i <= n; ++i)
{
cin >> a[i];
}
for (int i = 1; i < n; ++i)
{
int u, v;
cin >> u >> v;
G[u].push_back(v);
G[v].push_back(u);
}
dfs1(r, 0);
dfs2(r, r);
st.build(1, 1, n);
for (int i = 0; i < m; ++i)
{
int op, x, y;
long long z;
cin >> op;
if (op == 1)
{
cin >> x >> y >> z;
update_path(x, y, z);
}
else if (op == 2)
{
cin >> x >> y;
cout << query_path(x, y) << endl;
}
else if (op == 3)
{
cin >> x >> z;
update_subtree(x, z);
}
else
{
cin >> x;
cout << query_subtree(x) << endl;
}
}
return 0;
}
以上c++代码为deepseek生成,请勿抄袭,请勿抄袭,请勿抄袭!!!以免成为洛谷的作弊者!!!
下一节课—— 函数
点赞,点赞,点赞!!!!!!!
球球了!!!!
求求了!!!!

QwQ QwQ