因为我是萌新的缘故吧,所以接触到搜索想到的第一个词就是
难如登天!







简单介绍一下搜索家庭
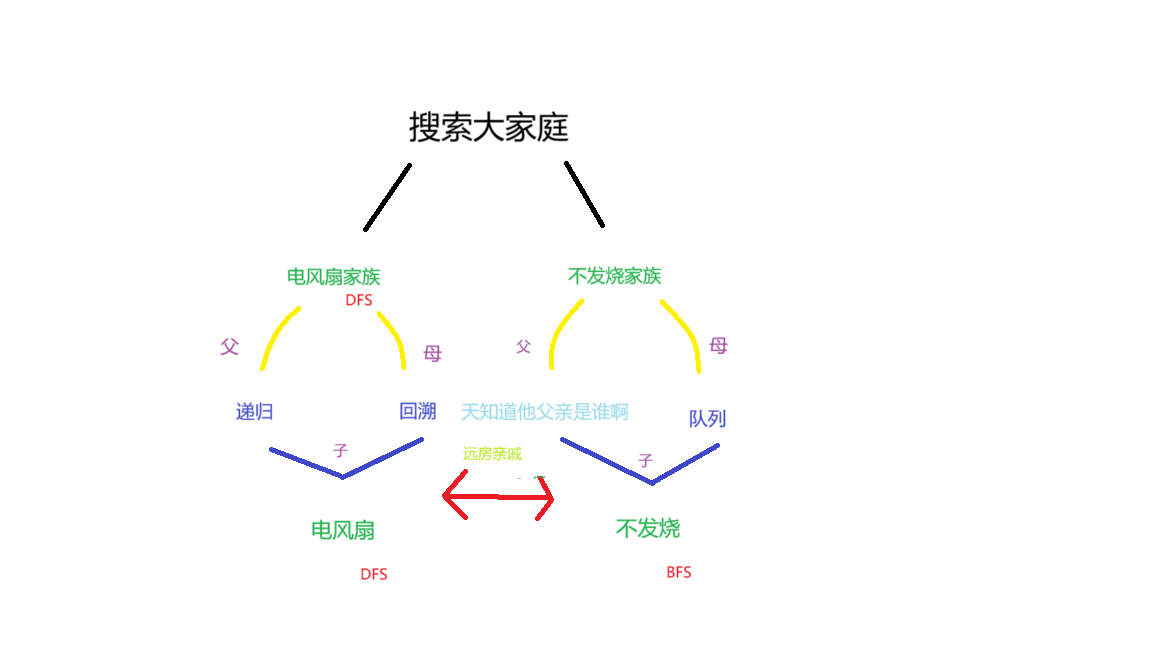
因为电风扇的父亲递归与栈是好兄弟,而栈是队列的哥哥 ̄□ ̄||,所以电风扇家族把不发烧一家接来住,从小一起长大的两兄弟性格不同,电风扇是直肠子,一条路走到黑、不撞南墙不回头;不发烧则善于求解最短与最小问题。下面来看他们的区别:
深度优先搜索(DFS)与广度优先搜索(BFS)的比较与应用
在计算机科学中,图(Graph)是一个重要的数据结构,广泛应用于网络、社交媒体、推荐系统等领域。在处理图的遍历和搜索时,有两种经典算法:深度优先搜索(DFS,Depth-First Search)和广度优先搜索(BFS,Breadth-First Search)。
一、深度优先搜索(DFS)
1. 原理
深度优先搜索是一种通过尽可能深地搜索图的分支来遍历节点的算法。即在访问一个节点后,优先访问其所有未访问的子节点,直到到达没有未访问子节点的节点,然后再回溯到前一个节点继续搜索。
2. 实现
深度优先搜索通常使用递归或栈(Stack)来实现。栈结构保留了待访问的节点。
DFS 代码示例:
就拿最水的《抽奖》做示范
题面
1. 抽奖
题目ID:9384 必做题100分
最新提交:
Accepted
100 分
历史最高:
Accepted
100 分
时间限制: 1000ms
空间限制: 524288kB
题目描述
时间限制:1s 空间限制:512M
题目描述:
在一个不透明的盒子里放入编号为 1~n 的 n 个球,每次只能摸一个球,然后把这个球放回盒子里摇匀后再摸,现在你可以抽取 n 次,请输出所有可能出现的结果。
数据格式:
输入一个整数(范围1到9),表示 n 个小球,抽取 n 次。
按字典序从小到大的顺序输出若干行可能出现的结果。
样例输入:
2
样例输出:
1 1
1 2
2 1
2 2
void dfs(int k) {
if (k == n + 1) { //判断边界条件
//输出答案
//返回
}
for (int i = 1; i <= n; i++) {
//存储答案
dfs(k+1); //用递归回溯
}
}
3. 特点
- 优点:
- 内存使用较少:在稀疏图中,DFS只需存储一条路径而不是所有节点。
- 实现简单:通过递归非常容易实现。
- 缺点:
- 可能导致栈溢出:在处理深度较大的图时,递归调方法可能导致栈溢出。
- 无法找到最短路径:DFS不保证找到从源点到指定点的最短路径。
二、广度优先搜索(BFS)
1. 原理
广度优先搜索是从起始节点开始,层层向外遍历所有邻接节点的方法。它首先访问起始节点,然后逐层遍历每一层的所有节点,直到图的所有节点都被访问。
2. 实现
广度优先搜索通常使用队列(Queue)来实现,以确保先访问节点的邻接节点。
BFS 代码示例:
一道经典的《我自闭了》
题面
1. 我自闭了
题目ID:8010 必做题100分
最新提交:
Accepted
100 分
历史最高:
Accepted
100 分
时间限制: 200ms
空间限制: 32000kB
题目描述
时间限制:0.2s 空间:32M
题目描述:
坠落在茫茫的毒瘤之海中,你自闭了。
但是小马哥不会自闭。
小马哥给了你一份毒瘤之海的地图,有 n 行 m 列,行号从 1 到 n,列号从 1 到 m。如果两个格子上下左右相邻,称为连通。例如 (x, y) 和 (x-1, y) (x+1, y) (x, y-1) (x, y+1) 都相邻。
每一个格子里面可能有毒瘤,也可能没有。毒瘤用 1 表示,否则用 0 表示。定义一个毒瘤连通块:任意两个毒瘤点都可以通过相邻连通关系互相到达的一个区块。那么请问最大的毒瘤连通块包含多少个毒瘤点。
可以参见样例详细理解题意。
输入格式:
第一行 n, m。(1≤n,m≤50)
接下来 n 行,每行 m 个 0 或 1。
输出格式:
一个数表示答案。
样例输入1:
5 4
0101
0111
1000
1100
0101
样例输出1:
5
int dx[] = {};
int dy[] = {};
//向量
int n, m;
char mapn[105][105];
int vis[105][105], cnt;
int x;
struct node {
int x;
int y;
}; //结构体,参数根据题目需要
void bfs(int x, int y) {
//下面是广搜模版
queue<node> qu; //定义队列
qu.push({x, y}); //元素入队
while (!qu.empty()) { //元素非空
cnt++;
node now = qu.front(); //取第一个元素值
qu.pop(); //出队
for (int i = 0; i < 4; i++) {
int now_x = now.x + dx[i];
int now_y = now.y + dy[i]; //定义现在的坐标
if ()
{
continue;
} //一些情况跳过
vis[now_x][now_y] = 1; //访问数组置一(根据题目来)
qu.push({now_x, now_y}); //元素入队
}
}
}
3. 特点
- 优点:
- 找到最短路径:在无权图中,BFS可以找到从起始点到目标点的最短路径。
- 完整性:BFS保证能够发现所有可以到达的节点。
- 缺点:
- 内存消耗高:在密集图中,BFS需要将所有节点存储在队列中,消耗更多的内存。
- 实现相对复杂:相比于DFS,BFS的实现稍显复杂。
三、DFS与BFS的比较
| 特性 | 深度优先搜索(DFS) | 广度优先搜索(BFS) |
|---|---|---|
| 使用的数据结构 | 栈(递归) | 队列 |
| 空间复杂度 | O(h),h为递归深度 | O(w),w为最大宽度 |
| 最短路径 | 不保证 | 保证 |
| 适用场景 | 解空间较大的问题 | 找最短路径或层级问题 |
| 简单性 | 较简单 | 较复杂 |
四、应用场景
- 深度优先搜索(DFS)
- 解题比赛和回溯算法:常用于棋类问题、数独等问题的解答。
- 图的连通性检测:检查图的连通组件和环的检测。
- 拓扑排序:在有向无环图中用于对节点进行排序。
- 广度优先搜索(BFS)
- 最短路径算法:用于无权图的最短路径问题,如社交网络中寻找朋友的推荐。
- 二叉树的层序遍历:输出树的每一层节点。
- 网络广播:在网络图中模拟消息的广播过程。
五、总结
深度优先搜索和广度优先搜索是图遍历中最基本与广泛使用的算法。DFS适合于需要探索整个图并寻找解的场景,而BFS则适用于需要找到最短路径的情况。在解决实际问题时,选择适合的算法将大大提高效率。
—————————————————————————————————————————————
但是电风扇与不发烧做事过于暴力,所以常常没在规定时间内完成任务,也就让我们经常超时,怎么办?

答:凉拌
因为他们太慢了,老师送了他们一把 大香蕉 不对,大剪刀,可以剪短时间复杂度!这就是剪枝 ![]() !
!
还送了他们一个瓶子,用来装答案,通过在搜索过程中保存已经计算过的状态的结果,避免对相同状态的重复计算,这就是记忆化搜索!
搜索优化
搜索剪枝和记忆化搜索是两种常用的优化技术,广泛应用于算法设计中,尤其是在解决组合问题、图形问题和动态规划等领域。这两种技术可以显著减少计算量,提升算法的效率。下面我们分别介绍这两种技术及其实现方式。
1. 搜索剪枝 (Pruning)
搜索剪枝是一种在搜索过程中减少无效计算的技术。它的基本思想是通过提前判断某些状态或路径不值得继续探索,从而避免无谓的搜索,节省时间和空间。
典型应用
- 深度优先搜索 (DFS):在解决问题如八皇后、数独等问题时,可以使用剪枝。
实现方式
在实现时,我们通常会设置一些条件,判断当前状态是否有可能导致合法解的生成,如果不可能,则剪去该状态的搜索。
示例 - 质数肋骨:
题面
3. 质数肋骨
题目ID:8719 必做题100分
最新提交:
Accepted
100 分
历史最高:
Accepted
100 分
时间限制: 500ms
空间限制: 262144kB
题目描述
农民约翰的母牛总是生产出最好的肋骨。你能通过农民约翰和美国农业部标记在每根肋骨上的数字认出它们。农民约翰确定他卖给买方的是真正的质数肋骨,是因为从右边开始切下肋骨,每次还剩下的肋骨上的数字都组成一个质数,举例来说: 7 3 3 1 全部肋骨上的数字 7331是质数;三根肋骨 733是质数;二根肋骨 73 是质数;当然,最后一根肋骨 7 也是质数。7331 被叫做长度 4 的特殊质数。
输入格式
写一个程序对给定的肋骨的数目 N(1≤N≤8)N(1≤N≤8), 求出所有的特殊质数。数字1不被看作一个质数。
输出格式
按顺序输出长度为 NN 的特殊质数,每行一个。
样例
Input 1
4
Output 1
2333
2339
2393
2399
2939
3119
3137
3733
3739
3793
3797
5939
7193
7331
7333
7393
样例解释
无
数据范围
保证 1≤N≤8
阅读题目可知,要减掉尾部的数,且必须是质数,N≤8,数字巨大,直接做包超时的,怎么办?
最后肯定之剩下首位数,第一位必须是质数,那已经排除了很多数,那第二为呢,肯定不能是0、2、4、5、6、8,否则能被2、5整除……以此类推减少了许多数,就不会超时了。
int a[] = {2, 3, 5, 7}; //首位的数
int b[] = {1, 3, 7, 9}; //后面可能的数
int n;
bool prime(int x) {
if (x == 1) return 0;
for (int i = 2; i <= sqrt(x); i++) {
if (x % i == 0) return 0;
}
return 1;
}
//判断质数
void dfs(int x, int num) {
if (x == n) {
cout << num << '\n'; //输出
return ;
}
for (int i = 0; i < 4; i++) {
int k = num * 10 + b[i]; //数字
if (prime(k)) {
dfs(x+1, k); //回溯
}
}
}
2. 记忆化搜索 (Memoization)
记忆化搜索是一种动态规划的方式,通过在搜索过程中保存已经计算过的状态的结果,避免对相同状态的重复计算,从而提升算法的效率。
典型应用
- 在解决斐波那契数列、最短路径、分治算法等问题中。
- 组合问题、排列问题,通过记录中间结果避免重复计算。
实现方式
在实现记忆化搜索时,我们通常会使用一个数据结构(如数组或哈希表)来存储已经计算过的结果,在后续计算中查找该数据结构即可。
总结
- 搜索剪枝可以显著减少无效状态的搜索,通过设定合理的条件提前结束搜索过程。
- 记忆化搜索则是通过缓存已经计算过的结果来避免重复计算,从而提高算法效率。
这两种技术常常结合使用,并根据具体问题的需求来选择适合的策略,以达到优化的目的。
